Know which AI agent spent the money.
Your provider invoice is one number. spaturzu is an LLM cost attribution SDK that breaks it down — every OpenAI, Anthropic, Bedrock, Gemini, and Mistral call attributed to the AI agent, run, and project that made it. It runs in-process — no proxy, no prompt changes — and your prompt content never leaves your servers.
Drop-in SDK for Node & Python. Sign in with email — your account is created on first use.
import OpenAI from "@spaturzu/sdk/openai";
// Swap one import — reads SPATURZU_API_KEY + OPENAI_API_KEY from env.
const openai = new OpenAI();
// Tag any call with the agent that made it — one line, no closure.
await openai.withAgent("support-triage").chat.completions.create({ /* … */ });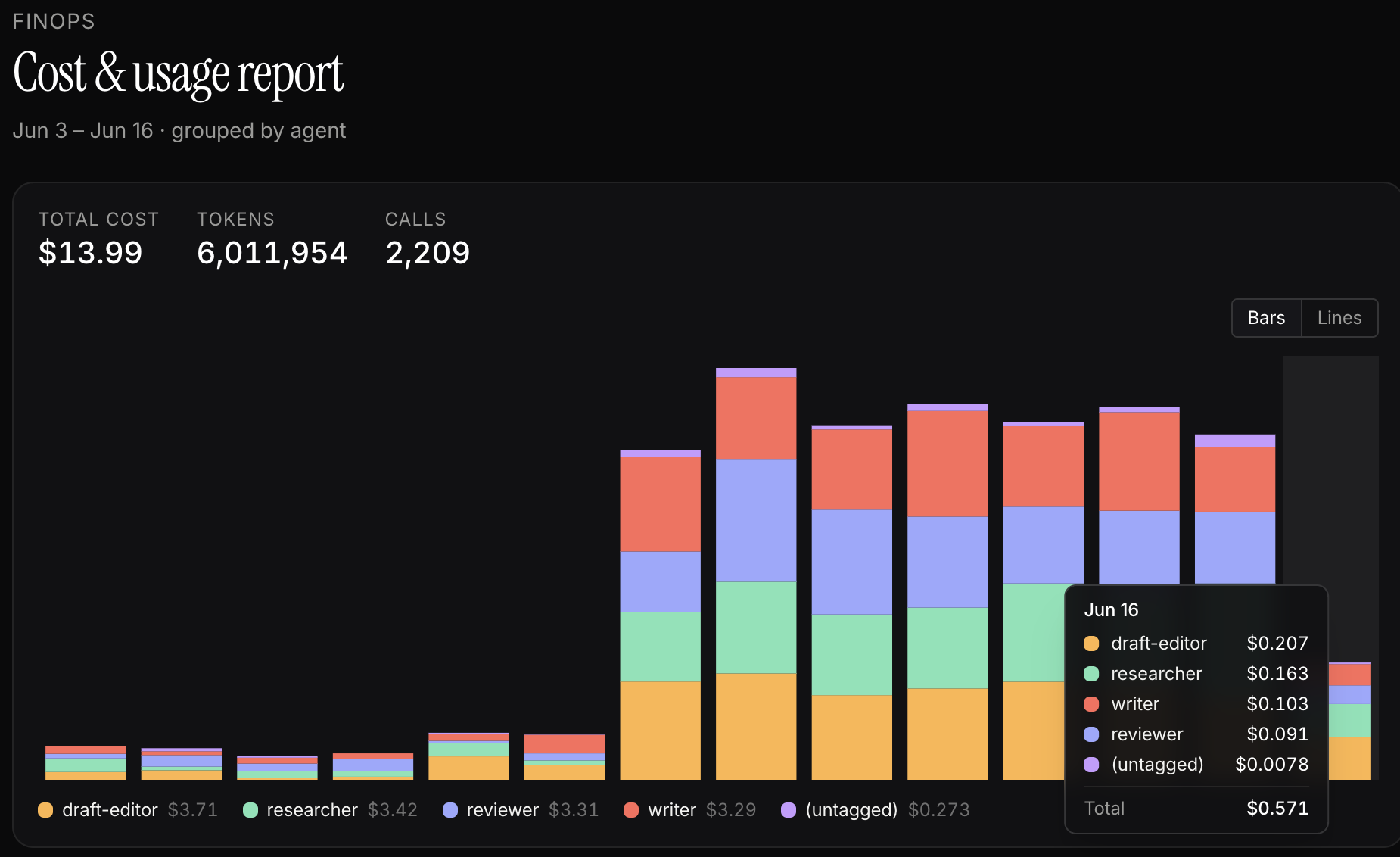
The invoice says $4,200. It doesn't say which agent.
You ship a handful of AI agents — a triage bot, a summarizer, a nightly report job. They all hit the same OpenAI key. At the end of the month you get a single bill and a spreadsheet's worth of guesses. Which agent regressed? Which run blew the budget? Which feature is quietly unprofitable? The provider dashboard can't tell you, because it never knew your agents existed.
spaturzu sits at the call site, not the invoice. It records token counts and cost as each request happens and tags it with the run and agent that made it — so the breakdown is there before the bill is.
Cost visibility, shaped like your code.
Per-agent attribution
7-day and 30-day cost rolled up per agent. See your most expensive agent the moment it becomes your most expensive agent.
Run-level traces
Every spaturzu.run() is a unit of work. Drill from a costly run into the individual provider calls that made it up.
Budgets & alerts
Daily or monthly caps per project. Cross a threshold and a webhook or Slack alert fires — before the overage, not after.
Drop-in SDK
Wrap your existing OpenAI, Anthropic, Bedrock, Gemini, or Mistral client. Node and Python. Your keys call the provider directly — prompt content never touches us.
Cost visibility without the privacy trade-off.
Many LLM cost and observability tools route your traffic through a proxy, store your prompts and responses on their backend, or both. spaturzu does neither. The SDK meters each call inside your own process — it turns prompt and response text into token counts locally and sends only those counts and the computed cost. Your prompts, system prompts, messages, and the model's responses never reach us; your provider key calls OpenAI, Anthropic, Bedrock, Gemini, or Mistral directly, and spaturzu is never in that path.
That keeps per-agent LLM cost attribution workable for teams with GDPR, HIPAA, or SOC 2 obligations — and anyone in a regulated or compliance-sensitive environment where prompt content can't be sent to a third-party tool. The sensitive text simply never leaves your servers. See exactly what we receive, and what we never see, in our privacy policy and terms.
Your app
makes the LLM call
spaturzu SDK
turns prompts & responses into token counts, locally
Full prompts + responses
your key — direct, no proxy
LLM provider
OpenAI · Anthropic · Bedrock · Gemini · Mistral
Token counts + cost
no prompt content
spaturzu
stores cost & usage — never prompt content
Three tools, three jobs.
Helicone is an LLM observability platform with a full-featured AI Gateway — great for debugging what an LLM actually said and routing across 100+ providers. Langfuse is an engineering platform for prompts, evals, and traces — great for getting the model's answers to be correct. spaturzu answers a different question: which agent spent the money, and how do we keep it under a hard cap — with no proxy in the request path and no prompt content ever leaving your servers.
| Capability | spaturzu | Helicone | Langfuse |
|---|---|---|---|
| Primary job | Per-agent cost + budgets + fallback | LLM observability + AI Gateway | LLM eng. platform (traces, prompts, evals) |
| Request path | In-process SDK; calls go direct to provider | Primary: AI Gateway (proxy). Async OpenLLMetry mode also available | Async SDK observer; never in the request path |
| Prompts stored on tool's backend | Never — only token counts + cost | Yes by default; opt-outs (Helicone-Omit-* headers, async mode) | Yes by default; opt-outs (SDK mask function, server-side masking) |
| Agent attribution model | run() frames; agentPath propagates to nested calls — designed for cost rollup | Manual: Helicone-Property-* headers + Sessions with slash-path | First-class agent observation type, auto-detected for many frameworks |
| Budget cap before the call | Typed BudgetExceededError, in-process, no proxy | Cost-based rate limit at the gateway (e.g. $5/hr/user), returns 429 | Not in scope — Langfuse is not in the request path |
| Cross-provider fallback | In-process, explicit pairwise translators across 5 providers (20 directional pairs) | AI Gateway covers 100+ providers via OpenAI-SDK translation; gateway-mediated | Not in scope — docs recommend pairing with a separate gateway |
| Full prompt/response inspection | Not in scope, by design | Core feature | Core feature |
| Prompt mgmt, evals, datasets | Not in scope | Prompts, Experiments, Datasets are GA. Evals are score ingestion | First-class: prompt mgmt, LLM-as-judge + human + custom evals, datasets |
Read the full breakdown: spaturzu vs Helicone · spaturzu vs Langfuse.
Reflects publicly documented behaviour as of May 2026. Spot a mistake? Let us know and we'll fix it.
From bill to breakdown in minutes.
Install the SDK
pnpm add @spaturzu/sdk — or pip install spaturzu. One dependency, no infrastructure to run.
Swap one import
Change openai to @spaturzu/sdk/openai (spaturzu.openai in Python) — construction and call sites are unchanged — then name your units of work with run() or .withAgent().
Watch the dashboard
Token counts, cost, and per-agent breakdowns appear within seconds of the first call.
Stop guessing at your LLM bill.
Sign in, drop the SDK into one agent, and see the attribution land on your first call.
Get started